Because at work I cannot enjoy the full copilot version and therefore cannot get transcripts (and minutes) from my teams meeting, i decided to give it a go with other tools.
I then discovered Whisper : « Whisper is an open‑source speech‑to‑text model designed by OpenAI to deliver accurate transcription across many languages. It handles real‑world audio remarkably well, even when recordings include background noise, accents, or imperfect microphone quality. Because it runs locally, it offers strong privacy and full control over your workflow. Its different model sizes—from tiny to large—let you balance speed and accuracy depending on your hardware and needs. »
Models can be downloaded here : tiny, base and small models are giving already really good results (before considering medium and large).
It is all about finding the right balance between time to process and accuracy.
Command line:
whisper-cli.exe --model "ggml-base.bin" --file "interview.wav" --output-txt --output-file "interview.txt" --threads 4 --language autoI strongly recommend to also look at this GUI version here : it uses an older whisper version which is delivering at first look better results (it uses GPU) compared to the latest ggml-org whisper versions : standard, blas (preferred) or cublas (you need cuda installed and a nvidia card).
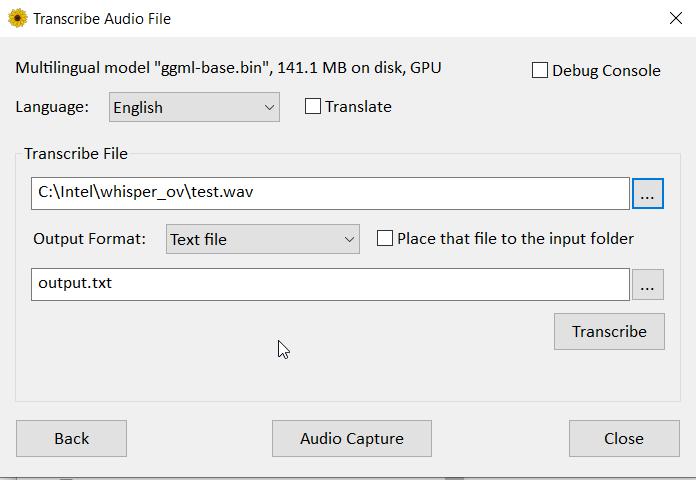
I might give it a try to openvino in a near futur (time to settle the proper python environement, script, models, etc).